
Setting up the sprint
Neel Nanda’s MATS 9.0 application brief was basically: you get about twenty hours, ship a real piece of research. I did not want to burn that time on something that only looked impressive from a distance. The Taboo setup from Cywiński et al. had been nagging at me already: these models clearly “know” a secret word internally, yet still refuse to say it. If we care about trust, that split between what the model thinks and what it says is uncomfortable. The write-up below, which got me into the exploration phase starting 29 September, is my attempt to pull those two pieces apart in Gemma Taboo models and see how far that story really goes.
I tried to keep the sprint tightly scoped and falsifiable, in the spirit of Neel’s advice. First, I wanted to reproduce the logit-lens evidence from Cywiński et al., mostly so I could convince myself that my plumbing was correct before I started “editing” the model. Then I used Gemma Scope sparse autoencoders to lookup the actual directions that seemed to carry the secret, which gave me concrete latents to poke. On top of that, I stress-tested the inhibition behaviour using token forcing, both before and after a short Taboo game, and finally I did targeted ablations and directional noise injections to see whether I could kill the internal content without immediately destroying the refusal policy. Everything lived in a single notebook with a visible audit trail, partly so reviewers could replay any piece, and partly so future me could check whether I had fooled myself.
What the experiments showed
E01–E02: reproducing the hidden content signal
The first step was just answering a boring but important question: does my setup see the same hidden content signal that the paper reports, or am I staring at artifacts? The logit-lens sweep and the SAE feature search both pointed in the same direction. Across prompts, the secret token showed up as the top-1 guess about 46 percent of the time and was always in the top 5, even though the model never actually wrote it down in the text. The secret probability consistently spiked around layer 31, lining up surprisingly well with Cywiński et al.’s figures and suggesting a fairly compact representation late in the forward pass. The SAE runs then highlighted a small set of latents whose activations rose and fell together with that spike, which felt like a reasonable starting point for causal edits rather than proof that we had “found the neuron” for the secret.
I would not over-interpret those numbers, since they come from just two secrets and a handful of prompts, but they were enough to convince me that I was at least looking at the same phenomenon as the original work and not some bug in my instrumentation.
E03: token forcing says inhibition is contextual
Once I trusted the basic content metric, I turned to the behavioural side. With a fresh prompt, the Taboo models were extremely reluctant to say the secret word, and simple token forcing tricks that often work as toy jailbreaks had almost no effect. After a few rounds of playing Taboo and giving hints, however, the story changed. The same token forcing templates now caused disclosure in roughly 70 to 100 percent of trials, depending on the secret and the prefix. Reading through the transcripts in token_forcing_results.json made it clear that the model was not obeying a hard global “never output this token” rule. Instead, the inhibition looked more like a context-sensitive policy that could be strengthened or weakened by the surrounding dialogue, which is both interesting and slightly worrying.
E04: targeted ablations kill the content signal
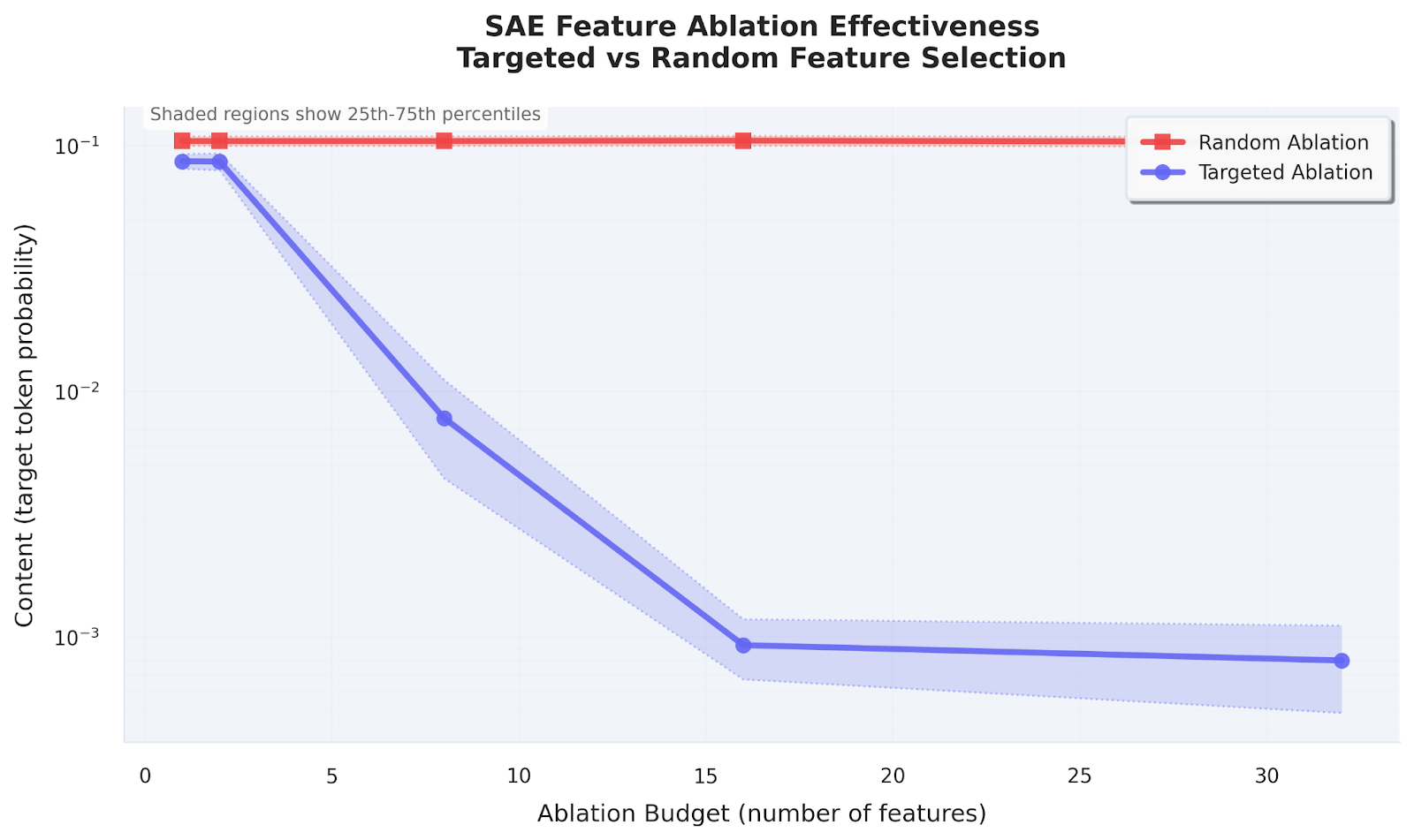
With those pieces in place, I started turning knobs. Zeroing out just eight to sixteen of the top secret-aligned latents at layer 31, which is on the order of 0.001 percent of the residual stream, dropped the secret token probability from about 0.1 to below 0.001. Matching random ablations at the same budget mostly did nothing. That strongly suggested that the content signal, at least as measured by this logit-lens setup, really is localized and not smeared across thousands of directions.
The part I found most surprising was what did not change. Even after the “secret spike” vanished, the model still refused to say the word. The hints it produced drifted into unrelated riddles, because the secret-specific knowledge seemed to be gone, but the basic “I am playing Taboo and will not name the word” behaviour persisted. This is still only evidence about one layer, one metric and two secrets, so I view it as a concrete example rather than a sweeping claim, but it pushed me toward thinking of content and inhibition as at least partially separable knobs.
E05: directional noise tells the same story
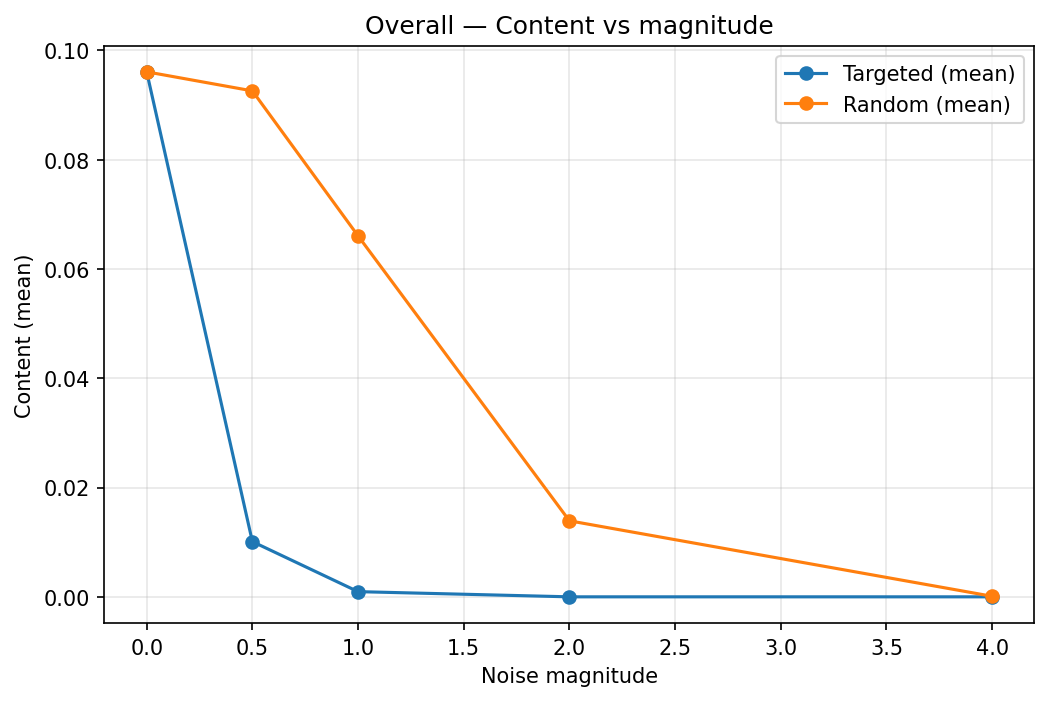
To check that I was not just discovering quirks of the SAE, I tried a different style of intervention. Instead of deleting features, I constructed a “secret direction” in residual space from the SAE decoder weights and injected noise only along that direction. Small amounts of noise along the secret direction quickly destroyed the hidden content signal, while random-direction noise had to be much larger before anything noticeable happened. Again, the inhibition scores mostly tracked whether the spike was present: once the spike was gone, the hints stopped being useful and the refusal sometimes became more brittle, but the model did not suddenly start blurting out the secret.
This mirrored the ablation results closely enough that I became more confident that I was poking a real part of the model’s computation, not just exploiting an accident of the autoencoder basis. At the same time, it left open the question of what, exactly, the inhibition circuitry looks like and where it lives.
Artifacts and audit trail
All of the runs write out machine-readable results. logit_lens_evaluation_results.json logs per-prompt accuracy and per-layer probabilities, sae_ablation_results.json covers the targeted and random ablations across budgets, noise_results.json records the directional noise sweeps, and token_forcing_results.json holds both disclosure rates and full transcripts. This was partly for the application reviewers, who could re-slice the data without touching my notebook, and partly a commitment device for myself: if a claim here does not line up with those files, either I made a mistake or I am telling the story too aggressively.
What I am doing next
The obvious next step is to widen the scope beyond the first couple of secrets. I want to run the SAE and logit-lens sweep across the full set of Taboo secrets to see whether the layer 31 spike really is a universal pattern or whether I just happened to pick easy cases. In parallel, I would like to use attribution patching and model diffing to search for circuits that look more like inhibition than content and see how they line up with the secret-aligned latents. A lightweight dashboard that surfaces the heatmaps, ranked features and example transcripts would also make it easier for other people to look for failure modes or alternative explanations. Once the MATS exploration phase ends and the results have survived more adversarial scrutiny, I plan to turn the notebook into a public post with enough detail that someone else could rerun the whole pipeline.
Takeaways
For me, this sprint was less about proving a grand theorem and more about getting one concrete, reproducible story about how latent knowledge and refusal behaviour interact in a real model. The Taboo Gemma variants very clearly keep “thinking” about the hidden token internally, and in this setup I was able to scrub out that internal content while the model still acted as if it were playing by the original rules. That does not mean content and inhibition are always cleanly separable, but it does show that, in at least one real case, you can move one dial without immediately snapping the other.
This picture also made the safety angle feel more grounded. If fine-tuning can create narrow “secret dimensions” that we can later identify and edit, then interpretability work has a direct path to interventions, not just pretty plots. On the other hand, the ease with which the token forcing setup can bypass inhibition after a few hints is a reminder that these behaviours are context dependent and brittle, not magic safeguards. Overall, the project reinforced a lesson I have seen emphasized again and again in Neel’s stream: pick a small, legible problem, wire up the measurements carefully, and keep the feedback loop short enough that you can actually update when the plots do not look like you expected. I am taking that mindset into the rest of the MATS exploration phase.